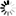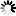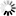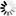Subsets are used to access selected members of a data set and to represent relationships between data set records. Each subset is a collection of indexes or pointers to the records of a single data set.
Subsets are either automatic or manual depending on their DASDL declaration. There are special scope rules for manual subsets, which are discussed under “Scope Rules for Manual Subsets” later in this section.
A subset that includes a where condition is called an automatic subset. An automatic subset contains one reference for each record in the associated data set that satisfies the where condition. Automatic subsets are maintained by the system. When a record is added to the data set, the system automatically evaluates the where condition. If the where condition is satisfied, a reference to the record is added to the subset. Records which are deleted from the data set are automatically deleted from the subset. When an existing record is modified, the where condition is reevaluated and a subset entry is added or deleted as necessary.
The following is an example of an automatic subset declaration:
STUDENTS DATA SET ( NAME ALPHA(20); GPA NUMBER(3,2); MAJOR ALPHA(20); ); HONOR-ROLL SUBSET OF STUDENTS WHERE GPA > 3.5 KEY IS NAME; ENGLISH-MAJORS SUBSET OF STUDENTS WHERE MAJOR = "ENGLISH" KEY IS NAME;
Subsets that do not specify a where condition are called manual subsets. Manual subsets must be maintained by user application programs. References to data set records are added to manual subsets by using the INSERT statement and are deleted from the subset by using the REMOVE statement.
Before a record is deleted from a data set it should first be removed from any manual subsets which reference it. The user should first verify that the record being deleted is not pointed to by a manual subset because the delete operation is allowed. If a subset refers to the deleted record, the results of future find operations using the manual subset are generally unpredictable. Manual subsets are frequently used in place of a link item when a single record must refer to a varying number of records simultaneously.
If the subset is an unordered list or bit vector and a new record now occupies the same location as the deleted record, the Enterprise Database Server does not detect that the new record is not the intended record. Unordered lists and bit vectors refer to a record by its location in the data set (with no key specified) and are similar to unprotected links. Other types of subsets can detect a KEYCOMPARE error if the KEYCOMPARE option is set.
The following example illustrates the DASDL syntax for a manual subset:
EMPLOYEE DATA SET
(
EMP-NUMBER NUMBER(7);
NAME ALPHA(20);
TITLE ALPHA(18);
SUPERVISOR IS IN EMPLOYEE VERIFY ON EMP-NUMBER;
SUBORDINATE SUBSET OF EMPLOYEE
KEY IS EMP-NUMBER,
ORDERED LIST;
);Several subsets can be declared for a single data set and each can be organized differently and can specify different keys. This enables a data set to be accessed in several different ways.
The following diagrams illustrate the syntax for declaring subsets:
Subset Declaration
──<subset name>─┬───────────┬─ SUBSET OF ─┬─<object data set>─┬────────►
└─<comment>─┘ └─<object set>──────┘
►─┬───────────────────────────────┬────────────────────────────────────┤
└─<set-subset physical options>─┘<object data set>
──<data set name>─┬──────────────────────────────────┬─────────────────►
└─ REORGANIZE ─┬───────────────────┤
└─ KEY ─┬─ CHANGED ─┤
└─ SAME ────┘
►─┬───────────────────┬─┬───────────────┬──────────────────────────────┤
└─<where condition>─┘ └─<subset type>─┘<object set>
──<set name>─┬──────────────────────────────────┬──────────────────────►
└─ REORGANIZE ─┬───────────────────┤
└─ KEY ─┬─ CHANGED ─┤
└─ SAME ────┘
►─┬───────────────────┬────────────────────────────────────────────────┤
└─<where condition>─┘<where condition>
── WHERE <Boolean expression> ─────────────────────────────────────────┤
<subset type>
──┬─ BIT VECTOR ────────────────────────────────────┬──────────────────┤
├─────────────┬─ LIST ─┬──────────────────────────┤
├─ UNORDERED ─┘ └─<key data>───────────────┤
└─<key clause>─┬──────────────────────────────────┤
│ ┌◄───────────── , ─────────────┐ │
└─┴─┬─/1\─<duplicates>─────────┬─┴─┘
├─/1\─<key data>───────────┤
└─/1\─┬─ INDEX RANDOM ─────┤
├─ I-R ──────────────┤
├─ INDEX SEQUENTIAL ─┤
├─ I-S ──────────────┤
├─ ORDERED LIST ─────┤
└─ O-L ──────────────┘<key clause>
── KEY ─┬──────┬─┬─<key item>─────────────┬────────────────────────────┤
└─ IS ─┘ │ ┌◄──── , ────┐ │
└─ ( ─┴─<key item>─┴─ ) ─┘<key item>
──┬─<field item name>───────┬─┬───────────────────────┬────────────────┤
├─<group item name>───────┤ ├─ ASCENDING ───────────┤
├─<numeric item name>─────┤ └─ DESCENDING ──────────┤
├─<real item name>────────┤ │
├─<record type item name>─┤ │
├─<RSN item name>─────────┘ │
└─<alpha item name>─┬──────────────┬─┬──────────────┤
├─ ASCENDING ──┤ └─<comparison>─┘
└─ DESCENDING ─┘<comparison>
──┬─ BINARY ─┬─────────────────────────────────────────────────────┬───┤ │ └─ COMPARISON ────────────────────────────────────────┤ ├─ LOGICAL ────┬─┬──────────────┬─┬──────────────────────────────┤ └─ EQUIVALENT ─┘ └─ COMPARISON ─┘ └─ ( ──<unsigned integer>── ) ─┘
<duplicates>
──┬─ DUPLICATES ─┬──────────────────┬──────────────────────────────────┤
│ ├─ FIRST ──────────┤
│ └─ LAST ───────────┤
└─ NO DUPLICATES ─┬───────────────┤
└─ KEYCHANGEOK ─┘<key data>
── DATA ─┬─<key data item>─────────────┬───────────────────────────────┤
│ ┌◄─────── , ──────┐ │
└─ ( ─┴─<key data item>─┴─ ) ─┘<key data item>
──┬─<alpha item name>───┬──────────────────────────────────────────────┤ ├─<Boolean item name>─┤ ├─<field item name>───┤ ├─<group item name>───┤ ├─<numeric item name>─┤ ├─<real item name>────┤ └─<RSN item name>─────┘
For information on the set-subset physical option, refer to “Set and Subset Physical Option” later in this section. The remaining elements of the syntax diagram are explained in the following text.