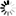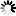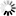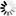Figures C–19 through C–21 illustrate ordered data sets.
The following figure illustrates an embedded ordered data set with no subblocks.
The following figure illustrates an embedded ordered data set with subblocks.

Ordered data set records are kept in a physical sequence based on a user-specified key without the necessity of utilizing a set. Ordered data sets can be either disjoint or embedded, but are normally embedded. The following figure illustrates the data record format for an ordered data set.

Normally ordered data set records consist of two parts: a data area (namely, I1 through In) and a key area (namely, K1 through Kn). The key part is composed of the key item copied from the data area and concatenated. Key items which specify the DESCENDING option are complemented; this keeps the items in collating sequence no matter what the ordering on each item.
If all of the following conditions are satisfied, the key items in the record are used directly and no key part will exist:
-
All key items are ascending.
-
All keys are alpha or unsigned numeric items.
-
All items are adjacent and in sequence from left to right in order of significance.
The data block format, NEXTBLOCKLOC layout, PRIORBLOCKLOC layout, block control word (BCW) layout, table block format, block 0 (zero) format, and available block format of an ordered data set are discussed in the following text.
Data Block Format
The following figure illustrates the data block format of an ordered data set.
Example 12. Ordered Data Set Data Block Format
WORD
0 NEXTBLOCKLOC
1 TABLESERIALNUM
2 PRIORBLOCKLOC
3 ---
. Block control words (BCWs),
. one for each subblock.
. A BCW count is maintained
. in the PRIORBLOCKLOC word.
---
---
.
. Available space.
.
---
---
.
.
. Data
. can be divided into subblocks,
. one for each BCW.
.
.
---NEXTBLOCKLOC Layout
The following figure illustrates the NEXTBLOCKLOC layout of an ordered data set.
Example 13. Ordered Data Set NEXTBLOCKLOC Layout
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A 47: 28 BAF
Block address of next block.
If equal to own address, then
last block in chain.
* 19: 04 Unused
1 = Data block
2 = Table block
3 = Available blockPRIORBLOCKLOC Layout
The following figure illustrates the PRIORBLOCKLOC layout of an ordered data set.
Example 14. Ordered Data Set PRIORBLOCKLOC Layout
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A 47: 28 BAF
Block address of prior block.
If equal to own address, then
first block in chain.
* 19: 04 Unused
Zeros.
B 15: 16 NUMSUBBLOCKS
Number of subblocks in this block.
Always 1 for disjoint or for embedded
whenever the block is not divided into
subblocks.Block Control Word (BCW) Layout
The following figure illustrates the block control word (BCW) layout of an ordered data set.
A A A A B B B B C C C C
A A A A B B B B C C C C
A A A A B B B B C C C C
A A A A B B B B C C C C
A 47: 16 ODFIRSTREC
Offset of first (rightmost) available space
in the subblock. If subblock is empty,
offset of first (leftmost) available slot.
B 31: 16 ODLASTAVAIL
Offset of last (leftmost) available space in
the subblock. If the subblock has been
combined with the next adjacent subblock,
then zero.
C 15: 16 ODLASTREC
Offset of last (leftmost) record in subblock.
If subblock is empty, then zero.
Note:
Records in blocks and subblocks are entered
in reverse order. That is, they are entered
sequentially from the end of the block/subblock
toward the front of the block/subblock.
Available space is always contiguous.
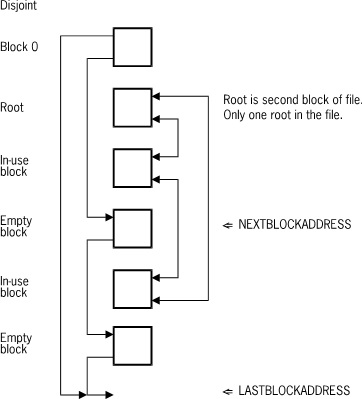
Disjoint data blocks are simply linked together. The root block is block 1. Each block contains a single BCW which keeps track of the first and last record in the block, and indicates how many available spaces are present.
The following figure illustrates the linking of disjoint data sets.
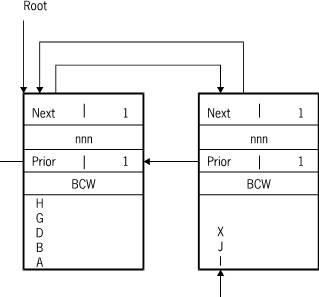
If a new record is added to a block and the block is full, the following actions occur:
-
A new block is allocated and linked to the existing block.
-
Some of the records in the existing block are moved to the new block. The number of records moved depends upon where the new record goes in the block.
-
If the new record goes in the last 10 percent of the block, the last 10 percent of the records are moved to the new block.
-
If the new record goes in the first 10 percent of the block, the last 90 percent of the records are moved to the new block.
-
Otherwise, all records that follow the new record are moved to the new block.
-
The new record is then inserted in either the old or the new block, depending on how the block is split.
The following figure illustrates the process for allocating a new block.
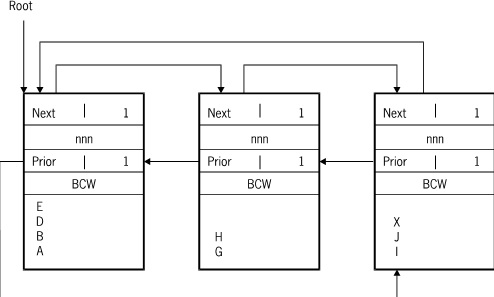
Valid records are always contiguous within blocks, as are available spaces. If a record is deleted, all subsequent records are moved to fill the vacancy. No attempt is made to consolidate blocks when a record is deleted. Data blocks are only returned to the available block chain when they are emptied.
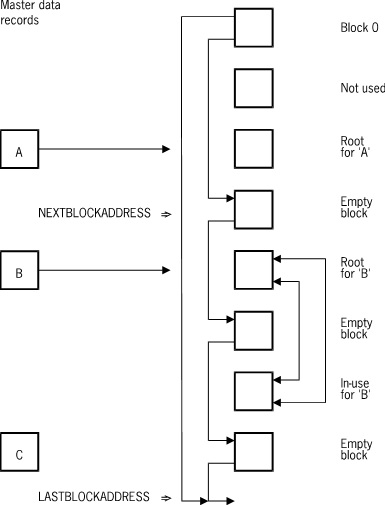
Embedded ordered data sets without subblocks resemble disjoint data sets except that there is one chain for each master, and each block contains records belonging to only one master. Each chain has one root block; it is pointed to by the master.
When the SUBBLOCKSIZE attribute is specified, each block is divided in subblocks. A block control word (BCW) exists for each subblock which indicates the location of valid data and available space in the subblock. Subblocks vary in size, but they are always a multiple of the SUBBLOCKSIZE attribute. For example, if the BLOCKSIZE attribute equals 25 records and the SUBBLOCKSIZE attribute equals 5, then subblocks can contain space for 5, 10, 15, 20, or 25 records. Masters containing from 1 to 5 records are allocated a subblock of size 5, those containing 6 to 10 records are allocated a subblock of size 10, and so on.
The following figure illustrates the layout of embedded data blocks that contain subblocks.
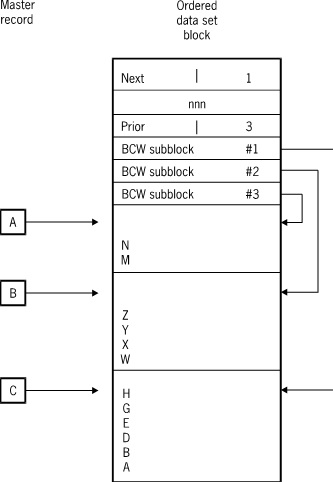
If adding new records results in outgrowing the subblock, then all records are moved to a subblock of the next larger size. The new subblock can be in the current block or some other block. Eventually the subblock can fill an entire block. When this happens, adding subsequent records causes entire blocks to be allocated and linked to the original block. All records in the overflow blocks belong to the master; overflow blocks are never partitioned in subblocks.
A subblock becomes available when all of its records are deleted or moved to another subblock. Table blocks are used to keep track of available space. Each table block contains a series of AA words that point to available subblocks. To simplify allocation, separate table blocks are created for each size subblock; one for subblocks 1*SUBBLOCKSIZE, another for subblocks 2*SUBBLOCKSIZE, and so on.
If a table block becomes full, a new table block is allocated and linked to the original. As table blocks are emptied, they are returned to the available block list.
Table Block Format
The following figure illustrates the table block format of an ordered data set.
Example 16. Ordered Data Set Table Block Format
WORD
0 NEXTBLOCKLOC
1 TABLESERIALNUM
2 Index of last valid table entry.
3 ---
.
.
. AA words pointing to BCWs
. of available subblocks.
.
. BAF = Block number of block
. containing empty subblock.
.
. WAF = Block control word index
. (BCWI) of BCW for empty subblock.
.
.
---
---
.
. Unused.
.
---Block 0 serves as head of the available block chain. In addition, it contains pointers to table blocks for ordered data sets which specify SUBBLOCKSIZE. Pointers to these table blocks begin at word 5 (SBSTART). One pointer exists for each size subblock. The pointer to the table block for subblocks of size X*SUBBLOCKSIZE is located at BLOCKZERO[5+X]. If the pointer for a particular size subblock is 0 (zero), then no subblocks of that size are available.
The following figure illustrates the block 0 (zero) format when the SUBBLOCKSIZE attribute is specified.
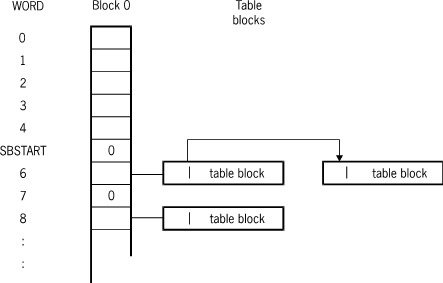
Block 0 (Zero) Format
The following figure illustrates the block 0 (zero) format of an ordered data set.
Example 17. Ordered Data Set Block 0 (Zero) Format
 |
WORD
0 Last Record Serial Number (RSN) allocated.
1 Reserved
2 NEXTBLOCKADDRESS
Address of last block deallocated.
3 LASTBLOCKADDRESS
Block past EOF.
Note The following words are used only when
a SUBBLOCKSIZE is specified.
4 LEFTOFFBLOCK
Block currently being allocated.
5 SBSTART
Zeros.
6 ---
.
.
. Links to table blocks.
.
.
---
---
.
.
. Unused
.
.
--- |
Available Block Format
The following figure illustrates the available block format of an ordered data set.
Example 18. Ordered Data Set Available Block Format
WORD
0 NEXTBLOCKLOC
1 TABLESERIALNUM
2 ---
.
.
. Unused
.
.
---Ordered Data Set Restrictions
The restrictions for ordered data sets are as follows:
-
Ordered data sets can be disjoint or embedded, but are normally embedded.
-
Variable-format records are not allowed.
-
Sets, subsets, and links cannot refer to ordered data sets since records can move as the result of create, delete, or modify operations.
-
One Access must be declared for each ordered data set.
The reasons for the restrictions on ordered data sets are as follows:
-
Ordered data sets use disk space efficiently provided the appropriate block size and subblock size are chosen. This is discussed in greater detail in the following paragraphs. No attempt is made to consolidate blocks or subblocks when a record is deleted. Blocks and subblocks are only reallocated when they have been emptied entirely; thus, extremely volatile files can benefit from periodic reorganization.
-
Record creation normally requires movement of existing records. Additional overhead is incurred if the size of the existing block or subblock is inadequate to contain the new record. Record modification is efficient, unless the key value changes. Record deletion normally requires movement of existing records.
-
The block size and subblock size can be chosen to minimize access time and disk space utilization. Correct values for these parameters depend upon the number of detail records for each master and whether the master data set is primarily accessed randomly or sequentially.
-
When the number of records for each master is large, the subblock size should not be specified. This applies no matter how the master records are accessed.
-
When the number of records for each master is small, the following rules apply:
-
For sequential access, subblock size should be specified if two or more subblocks can be contained in a block.
Making the block size as large as possible, commensurate with main memory usage, minimizes I/O time since records for several masters can be loaded with a single I/O operation.
-
For random access, subblock size should not be specified and block size should be small to save memory space and avoid unnecessary I/O transfer time.
-
-
If the number of details for each master varies widely, subblock size should be used to enhance both I/O time and disk space utilization.
For example, the best specification is BLOCKSIZE = 40 and SUBBLOCKSIZE = 4 for an ordered data set under the following circumstances:
-
The data set contains from 1 to 400 details in each master.
-
80 percent of the masters contain less than 4 details.
-
5 percent of the masters contain more than 40 details.
-
The record size is not large.
For 80 percent of the masters, when there has been a sequential load and the masters are being scanned sequentially, an I/O operation which loads its details also loads detail records for the next nine masters. For the remaining masters having 40 or fewer detail records, at most a single I/O operation for each master is required. Only 5 percent of the masters require more than one I/O operation to load all details. Even for a master with 400 details, only 10 I/O operations are required. Specifying subblock size saves disk space as well, since different masters can share blocks.
-
-
The fastest way to load an ordered data set is in ascending sequence.