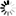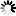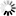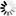The automatic sets of the Enterprise Database Server can represent one-to-N relationships between two data sets or on a single data set using two automatic sets—one for each direction the relation can be traversed.
One-To-N Relationships on a Single Data Set
The system file naming structure gives rise to a logical tree structure where each node of the tree has an associated identifier with a maximum of 17 EBCDIC characters. It is desirable to physically store the actual identifiers in such a way as to conserve storage, because eventually there is a very large number of file names stored. Therefore, instead of using a data set of file titles, consider using a data set of nodes containing the file identifiers. There is a relationship between the nodes of this data set that give the arcs in the tree‑of‑file titles. This situation can be represented by Figure D–4.
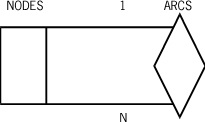
A single file identifier can appear at several different nodes. This can easily be seen from the two file titles A/A and A/C/A. The identifier A appears at three different nodes in the tree structure for the two titles as shown in Figure D–5.
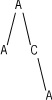
Therefore, it is natural to introduce a unique node number called NODENUM.
By convention, let there be two virtual nodes that are not actually stored and that have node numbers 0 and 1. Node 0 is the ultimate parent node of all system files, and node 1 is the ultimate parent node of all usercode files. A file title is the concatenation of all the node identifiers on the path from the root node to a leaf node of the tree.
It is preferable to avoid storing an identifier twice if it is both a directory and a final identifier of a file title. For example, for the two file titles A and A/B you want to store A only once. (Note that with the file titles A, A/B, and A/B/A, identifier A is stored twice.) This can be accomplished by introducing two flags in the nodes record. DIRFLAG indicates whether the identifier of the node is part of a longer file title or not, and FILEFLAG indicates whether the identifier is the final identifier of a file title or not. When both flags are on in a node record, you have eliminated the need for storing the identifier a second time. (Actually, only FILEFLAG is necessary. However, DIRFLAG can make lookups more efficient. If DIRFLAG is reset, then there are no more nodes below the current one; thus, an unnecessary call on the FIND operator can be avoided for leaf nodes, since a NOTFOUND exception would result.)
Besides its own unique identifier, NODENUM, each node has a unique (immediate) parent node, called PARENTNODENUM.
You can represent the preceding relationship with a DASDL description as follows:
NODES DATA SET
(
NODENUM FIELD(24);
PARENTNODENUM FIELD(24);
ID ALPHA(17);
FLAGS FIELD
(
DIRFLAG;
FILEFLAG;
);
);
| Note: | Field items have been used in the DASDL description to maximize efficiency in storage space utilization. |
For example, suppose you store the following file titles, in order, and assign unique node numbers consecutively starting at 2:
*A *A/B/C *A/B/D *A/Z *X
The following records are stored in the NODES data set:
|
NODENUM |
PARENT NODENUM |
ID |
DIRFLAG |
FILEFLAG |
|---|---|---|---|---|
|
2 |
0 |
A |
TRUE |
TRUE |
|
3 |
2 |
B |
TRUE |
FALSE |
|
4 |
3 |
C |
FALSE |
TRUE |
|
5 |
3 |
D |
FALSE |
TRUE |
|
6 |
2 |
Z |
FALSE |
TRUE |
|
7 |
0 |
X |
FALSE |
TRUE |
This situation represents the following tree, where only NODENUM and ID are shown for each node for the sake of clarity:
0,*
/ \
7,X 2,A
/ \
6,Z 3,B
/\
4,C 5,D| Note: | The node with NODENUM=0 is implicit and is not stored in the NODES data set. |
The arcs relationship can be represented with the following two sets:
ARCSET SET OF NODES KEY(PARENTNODENUM, ID); NODESET SET OF NODES KEY(NODENUM);
By default the two sets are index sequential structures with no duplicate keys allowed. Retrievals using index sequential structures are very efficient if the selection expression is FIRST, NEXT, PRIOR, or LAST. When a key condition is specified, the retrievals are very efficient if the key condition allows at least a partial binary search on the index. A binary search on the index results if, and only if, the following four conditions are met when a key condition is specified:
-
The first N of the M key items are used once each in Boolean primaries (which are either equalities or inequalities).
-
All the primaries are connected by the logical connective AND, and the connectives NOT and OR do not appear.
-
The primaries for the first N‑1 key items are equalities.
-
The primary for the Nth key item is as follows:
-
If the key item is ascending and the operation is a FIND FIRST or a FIND NEXT, or if the key item is descending and the operation is a FIND LAST or a FIND PRIOR, then the relational operator is one of equal to (=), greater than (>), or greater than or equal to (>=).
-
If the key item is descending and the operation is a FIND FIRST or a FIND NEXT, or if the key item is ascending and the operation is a FIND LAST or a FIND PRIOR, then the relational operator is one of equal to (=), less than (<), or less than or equal to (<=).
For example, the following selection expressions specifying key conditions on ARCSET are the most efficient. To find the first or the next ARCSET at the specified position, use any of the following expressions:
PARENTNODENUM = V1 AND ID = V2 PARENTNODENUM = V1 AND ID > V2 PARENTNODENUM = V1 AND ID GEQ V2 PARENTNODENUM = V1 PARENTNODENUM > V1 PARENTNODENUM GEQ V1
To find the last or the prior ARCSET at the specified position, use any of the following expressions:
PARENTNODENUM = V1 AND ID = V2 PARENTNODENUM = V1 AND ID < V2 PARENTNODENUM = V1 AND ID LEQ V2 PARENTNODENUM = V1 PARENTNODENUM < V1 PARENTNODENUM LEQ V1
If ID is a descending key item, the same selection expressions would be optimized except that > would be replaced by <, < by>, GEQ by LEQ, and LEQ by GEQ.
Thus, given a node X, the nodes immediately below it can be found simply and efficiently (in alphabetical order of identifier) as follows:
SET ARCSET TO BEGINNING;
DO BEGIN
FIND NEXT ARCSET AT PARENTNODENUM=X : RSLT;
IF NOT RSLT THEN
BEGIN
[PROCESS NODES RECORD]
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);And given a node Y, its parent can be found as follows:
GET NODES(PARENTNODENUM : =PARENTNODENUM); FIND NODESET AT NODENUM=PARENTNODENUM : RSLT;
The unique node numbers are created by the user-written update program. Because of creations and deletions over time, the maximum node number is continually increased. In theory, any fixed field size for the node number is eventually exceeded. To avoid this, it is desirable to reuse node numbers. This can be accomplished by introducing a flag in the node record called INUSEFLAG. INUSEFLAG=1 indicates that the node is in use. INUSEFLAG=0 indicates that the node is not in use, but it is not to be deleted in the Enterprise Database Server sense. Introduction of INUSEFLAG results in the following DASDL description:
NODES DATA SET
(
NODENUM FIELD(24);
PARENTNODENUM FIELD(24);
ID ALPHA(17);
FLAGS FIELD
(
DIRFLAG;
FILEFLAG;
);
INUSEFLAG NUMBER(1);
);
ARCSET SET OF NODES KEY(INUSEFLAG, PARENTNODENUM, ID);
NODESET SET OF NODES KEY(INUSEFLAG, NODENUM);The nodes immediately below a node X can be found as follows:
SET ARCSET TO BEGINNING;
DO BEGIN
FIND NEXT ARCSET AT INUSEFLAG=1 AND
PARENTNODENUM=X : RSLT;
IF NOT RSLT THEN
BEGIN
[PROCESS ARCS RECORD]
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);The parent node of a node Y can be found as follows:
GET NODES(PARENTNODENUM : = PARENTNODENUM); FIND NODESET AT INUSEFLAG=1 AND NODENUM=PARENTNODENUM;
A new node can be allocated as follows:
LOCK FIRST NODESET AT INUSEFLAG=0 : RSLT;
IF RSLT THEN
BEGIN
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);
LOCK LAST NODESET : RSLT;
IF RSLT THEN
BEGIN
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);
[NODES DATA SET ENTIRELY EMPTY.
STORE FIRST NODE WITH NODENUM=1.]
END ELSE
BEGIN
GET NODES(X : = NODENUM);
[ALL NODES IN USE. CREATE A NEW NODE WITH
NODENUM=X+1.]
END;
END ELSE
BEGIN
[THIS NODE NOT IN USE. REUSE THIS NODE.
CHANGE INUSEFLAG FROM 0 TO 1, BUT KEEP
SAME VALUE FOR NODENUM.]
END;The following procedure can be used to search for a file title. Whether the file title is found or not, it indicates the last node at which there is a common identifier. This facilitates storing the new title if it is not found.
EBCDIC ARRAY E[0: 13, 0: 16]; % E[n,*] holds the nth
% identifier of the title
% (n > 0).
PROCEDURE SEARCH(E, N, LASTCOMNODE, LASTLEVMATCHED);
VALUE N;
EBCDIC ARRAY E[0,0]; % holds identifiers
REAL
LASTCOMNODE, % node num of last common node
LASTLEVMATCHED, % index of last identifier
MATCHED
N; % number of identifiers
BEGIN
REAL I, NODENUM;
BOOLEAN DIRFLAG, RSLT;
DIRFLAG : = TRUE;
I : = 1;
DO BEGIN
FIND ARCSET AT INUSEFLAG=1 AND
PARENTNODE=NODENUM AND
ID=E[I,0] : RSLT;
IF NOT RSLT THEN
GET NODES
(NODENUM : = NODENUM
,DIRFLAG : = DIRFLAG
);
END UNTIL (I : = *+1) > N OR RSLT OR NOT DIRFLAG;
LASTLEVMATCHED : = I-1;
LASTCOMNODE : = NODENUM;
IF RSLT THEN
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);
END;One-To-N Relationships Between Two Data Sets
In an archive database it is necessary to store information about where each file is backed up. This can be done by using a data set called BACKUPINFO. Each record of BACKUPINFO contains information about one backup copy of a file. The unique node number of the last node of the file title can be used to relate the file to its backup information in a one-to-N fashion. In addition, it would be desirable to be able to obtain a list of all the files backed up on a particular serial number tape or pack. Finally, it should be easy to obtain the backup information for all files from a particular pack family or from disk (in case the entire family is lost, for example). The file structure can be represented by Figure D–6.
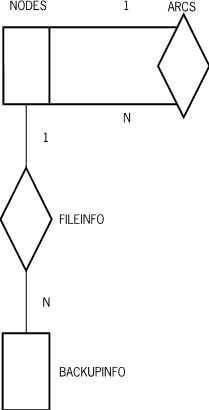
In addition to the data set nodes and its sets, the following data set description would be added to the archive DASDL description:
BACKUPINFO DATA SET
(
NODENUM FIELD(24);
SERIALNUM ALPHA(6);
DATETIME GROUP
(
YEAR NUMBER(2);
MONTH NUMBER(2);
DAY NUMBER(2);
HOUR NUMBER(2);
MINUTE NUMBER(2);
SECOND NUMBER(4,2);
);
FILEKIND ALPHA(17);
CYCLE NUMBER(4);
VERSION NUMBER(2);
FAMILYID ALPHA(17);
MEDIATYPE ALPHA(6);
FAMILYINDEX NUMBER(3);
BASESERIAL ALPHA(6);
NEXTSERIAL ALPHA(6);
MEDIADATE GROUP
(
MEDIAYEAR NUMBER(2);
MEDIAMONTH NUMBER(2);
MEDIADAY NUMBER(2);
);
);
FILEINFO SET OF BACKUPINFO KEY(NODENUM,
DATETIME DESCENDING);
SERIALSET SET OF BACKUPINFO KEY(SERIALNUM) DUPLICATES;
FAMILYSET SET OF BACKUPINFO KEY(FAMILYID) DUPLICATES;DATETIME has been included in the FILEINFO set as a descending key item to facilitate retrieval of the backup information about a file in reverse time order.
Duplicates have been allowed for SERIALSET and FAMILYSET but not specified as first or last, because that is more efficient for STORE and DELETE operations if the number of duplicates that can occur is large. However, the use of duplicates costs one extra word for each key entry.