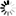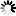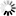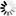The following text discusses the effect of many-to-many (M-to-N) relationships on a single data set and between two data sets.
M-To-N Relationships on a Single Data Set
The relationship data set technique can also be used for M-to-N relationships for a single data set. For example, consider a product structure. Each part can be composed of a number of other parts which are in turn composed of other parts, and so on. The inverse of this relationship is the relation of each group of parts to the higher part in which it is used. This situation can be represented at the data set level by Figure D–7.
At the record level the situation can be represented by Figure D–8.
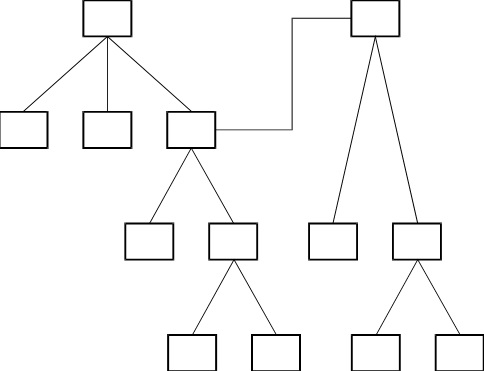
All the rectangles in the figure are records of the PARTS data set. The lines going down from a part indicate the immediate components of the part. One record is stored in the PARTSLIST data set for each such line; that is, for each immediate subpart of a composite part. The list of parts one level down (immediate subparts) of any given part is unique, and the corresponding set of PARTSLIST records is stored in the PARTSLIST data set only once. Thus, if two different composite parts have a common subpart, the entire parts list tree for the common subpart is shared by both composite parts. Common subparts are shared to conserve storage and to avoid the problem of inconsistent copies. Sharing of common subparts makes the relationship M-to-N instead of one-to-N.
The situation can be represented in DASDL as follows, assuming that the part number, PARTNUM, uniquely identifies each part:
PARTS RANDOM DATA SET
(
PARTNUM NUMBER(8);
DESCRIPTION ALPHA(28);
PRICE REAL;
.
.
.
);
PARTSKEY ACCESS TO PARTS KEY PARTNUM MODULUS 1500;
PARTLIST DATA SET
(
PARTNUM NUMBER(8);
SUBPARTNUM NUMBER(8);
);
EXPSET SET OF PARTSLIST KEY(PARTNUM, SUBPARTNUM);
WUSET SET OF PARTSLIST KEY(SUBPARTNUM, PARTNUM);The following ALGOL procedure can be used to explode a part, that is, to process all the parts of which it is composed down to the indivisible parts. The parts list tree is traversed in depth-first order.
PROCEDURE EXPLODE(PARTNUM, LEVEL);
VALUE PARTNUM, LEVEL;
REAL PARTNUM, LEVEL;
BEGIN
REAL SUBPARTNUM;
BOOLEAN RSLT;
FIND PARTSKEY AT PARTNUM=PARTNUM;
[PROCESS PARTS RECORD]
DO BEGIN
FIND KEY OF FIRST EXPSET AT
PARTNUM=PARTNUM AND
SUBPARTNUM > SUBPARTNUM : RSLT;
IF NOT RSLT THEN
BEGIN
GET PARTSLIST(SUBPARTNUM: =SUBPARTNUM);
EXPLODE(SUBPARTNUM, LEVEL+1);
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);
END;The procedure can be called as follows to explode part X:
EXPLODE(X, 1);
The procedure is recursive, and the value of the LEVEL parameter indicates the current recursive depth in the parts list tree. (Since subparts are shared, the level cannot be stored in the database—a subpart can occur at many different levels in the same or different parts list trees.) The find operation on EXPSET is not affected by the fact that each recursive call on the explode procedure changes the current path of EXPSET. By saving two values local to the procedure—the part number of the part being exploded at that level and the last part number processed in its one-level-down parts list—enough information is saved to eliminate the need for the old path. The procedure depends upon the key of EXPSET being unique, because the procedure skips any duplicates.
The explode procedure is efficient if a reasonable number of buffers is specified in the DASDL description for EXPSET. This number should be at least a few more than the maximum number of levels in the product structure. (Often the maximum number of levels in the product structure is relatively small.)
The following ALGOL procedure could be used to implode a part, that is, to process all parts of which the part is a subpart, all parts of which those parts are subparts, and so on, all the way down to the parts which are not a subpart of any other part. (This is often referred to as the where-used list.)
PROCEDURE IMPLODE(PARTNUM, LEVEL);
VALUE PARTNUM, LEVEL;
REAL PARTNUM, LEVEL;
BEGIN
REAL HIGHERPARTNUM;
BOOLEAN RSLT;
FIND PARTSKEY AT PARTNUM=PARTNUM;
[PROCESS PARTS RECORD]
DO BEGIN
FIND KEY OF FIRST WUSET AT
SUBPARTNUM=PARTNUM AND
PARTNUM > HIGHERPARTNUM : RSLT;
IF NOT RSLT THEN
BEGIN
GET PARTSLIST(HIGHERPARTNUM : = PARTNUM);
IMPLODE(HIGHERPARTNUM, LEVEL+1);
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);
END;The implode procedure uses the same techniques as the explode procedure, but uses WUSET instead of EXPSET. It can be called to produce the full level where-used list of the part with part number Y as follows:
IMPLODE(Y, 1);
A random data set is used for the PARTS data set because no matter what technique is used to explode or implode, the accesses on the PARTS data set are random (as opposed to sequential). Random data sets are designed to retrieve the desired record in one disk access. Although, in some cases, they can use more than one disk access. A set and data set combination accessed randomly would typically take approximately two disk accesses on the average.
Note that index sequential sets could be added against the PARTS data set, even with key PARTNUM. This is desirable, for example, if you want to print a report on all the parts in part number order.
M-To-N Relationships Between Two Data Sets
There are often important M-to-N relationships between the records of two data sets. For example, consider the example of products and orders discussed under the heading “Update Anomalies” earlier in this appendix. Suppose you have the following DASDL description:
ORDERS DATA SET ( ORDERNUM NUMBER(6); DUEDATE NUMBER(6); ORDERDATE NUMBER(6); CUSTOMER NUMBER(6); ); ORDERKEY SET OF ORDERS KEY ORDERNUM; PRODUCTS DATA SET ( PARTNUM NUMBER(8); DESCRIPTION ALPHA(24); PRICE REAL; ); PRODUCTKEY SET OF PRODUCTS KEY PARTNUM;
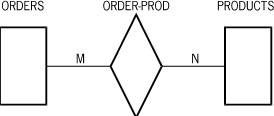
Suppose that, in addition, you can have a certain number of products associated with a given order, and you have a certain number of orders associated with each product. Figure D–9 represents this situation at the data set level.
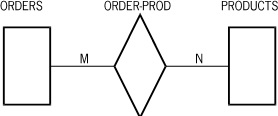
Figure D–10 illustrates the record-level status, depending on the current contents of the database.
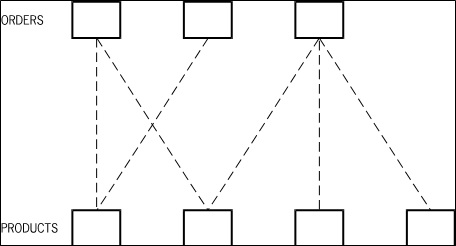
Each rectangle represents a product of an order record, and each line represents an association between the two.
You can represent this situation in the Enterprise Database Server in a variety of ways. The first way that occurs to many people is to use embedded manual subsets. However, this is typically not the best method. Usually, the best method is to add a disjoint data set, which is referred to as the relationship data set. A record is stored in the relationship data set for each connection between a pair of records, one from each of the other two data sets. Two automatic sets against the relationship data set are used to provide efficient retrieval when going from either of the original data sets to the other. The keys of the two sets are the unique keys of the original two data sets concatenated in both orders (one order for each set).
The relationship data set which stores the connections between the original two data sets ORDERS and PRODUCTS (illustrated in Figure D–10) could be represented as follows:
ORDER-PROD DATA SET ( PARTNUM NUMBER(8); ORDERNUM NUMBER(6); ); ORDERPRODKEY SET OF ORDER-PROD KEY(ORDERNUM,PARTNUM); PRODORDERKEY SET OF ORDER-PROD KEY(PARTNUM,ORDERNUM);
Then, for example, you could use the following ALGOL fragment to find all the products associated with the order whose order number is X:
REAL X, PARTNUM;
BOOLEAN RSLT;
SET ORDERPRODKEY TO BEGINNING;
DO BEGIN
FIND KEY OF NEXT ORDERPRODKEY AT ORDERNUM=X : RSLT;
IF NOT RSLT THEN
BEGIN
GET ORDER-PROD(PARTNUM: =PARTNUM);
FIND PRODUCTKEY AT PARTNUM=PARTNUM;
[PROCESS PRODUCTS RECORD]
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);Similarly, you could find all orders for the product whose product number is Y as follows:
REAL Y, ORDERNUM;
BOOLEAN RSLT;
SET PRODORDERKEY TO BEGINNING;
DO BEGIN
FIND KEY OF NEXT PRODORDERKEY AT PARTNUM=Y : RSLT;
IF NOT RSLT THEN
BEGIN
GET ORDER-PROD(ORDERNUM: =ORDERNUM);
FIND ORDERKEY AT ORDERNUM=ORDERNUM;
[PROCESS ORDERS RECORD]
END;
END UNTIL RSLT;
IF REAL(RSLT).DMERROR NEQ NOTFOUND THEN
DMTERMINATE(RSLT);The preceding two program fragments illustrate the FIND KEY OF feature of keyed index sets. Accesses are made only to the index set when this construct is used—the data set is not accessed at all. Only key items in the key of the index set (plus key data items, if any) are transferred to the user work area; however, in many cases, they are all the items that are needed. Thus, the relationship data set technique is efficient as well as simple and easy to understand.