Disjoint structures are usually preferred over embedded structures for several reasons.
Disjoint data sets can be represented by simple tables as mentioned previously. This is a much simpler structure than a hierarchy, which is what results when embedded structures are involved.
Embedded structures are not required to represent one-to-1, one-to-N, or M-to-N relationships. These relationships can be achieved by using disjoint structures. The relationship data set technique illustrated previously is often superior to using embedded structures. For example, consider the product structure example discussed previously. A DASDL description using embedded subsets could be as follows:
PARTS RANDOM DATA SET
(
PARTNUM NUMBER(8);
.
.
.
SUBPARTS SUBSET OF PARTS KEY(PARTNUM);
HIGHERPARTS SUBSET OF PARTS KEY(PARTNUM);
);
PARTSKEY ACCESS TO PARTS KEY(PARTNUM) MODULUS 1500;The embedded subsets cannot represent the additional relationship information, such as quantity, build level, operation number, and item number needed in a practical parts listing database. But even if that information is not required, it takes two inserts—one in each subset—to get both the parts list and the where-used connections whereas it takes a create and store operation previously used in the PARTSLIST data set. Thus there is more chance for error. Also, doing the insert is a little more complicated than a create and store operation because two records have to be made current first. Finally, the implosions and explosions could be less efficient if the previously described subsets are used. Using a subset to find a parts record changes the current record for the parts work area. The old parts record has to be made current again after each retrieval of a subpart (or higher part) to access its subset again to get the next part under (or above) it.
Disjoint structures can be entered directly. Embedded structures cannot—a master record must first be made current. Embedded structures, therefore, restrict the retrievals that can be made easily by imposing extra constraints on the structure of the database.
A practical consideration is disk space utilization. Embedded structures tend not to use space as efficiently as disjoint structures. The index tables for embedded sets and subsets do not share blocks between masters, and all blocks in the Enterprise Database Server start on a segment boundary. Suppose the master data set has one million records, and each master record has at least one key entry in its embedded set. Then there are at least one million blocks in the file for the embedded set. Embedded standard data sets use space efficiently by allowing blocks to be shared between masters. However, at least one embedded set is required against them. Embedded unordered data sets do not require a set against them, and do not allow blocks to be shared between masters. Embedded ordered data sets are the most space-efficient embedded structure because of the subblocking technique they allow, but no sets or subsets are allowed against them.
Another practical consideration is recovery from disasters. Automatic sets and subsets contain 100 percent redundant information except for the order of duplicates, if allowed. And except for the order of duplicates, if any, they can be re-created from their data set quickly and easily using a DASDL Reorganization. When embedded structures and links are involved, the whole database cannot be recovered in this way. This can be an extremely important consideration.
Key items cannot be changed unless duplicates are allowed on the set or subset. If no duplicates are what is really wanted, you can get around this by not allowing duplicates, and by performing a delete operation, a re-create operation, a change of key items, and a store operation in series. This cannot always be done for master records because a master record cannot be deleted unless all its embedded structures are empty.
An embedded data set can often be turned to a disjoint data set by adding data items which uniquely specify a master record, and prefixing the key of a set against it with these items. For example, consider the following DASDL description:
THINGS DATA SET
(
THINGID NUMBER(8);
.
.
.
NARRATIVE DATA SET
(
LINENUM NUMBER(3);
LINE ALPHA(72);
);
NARRATIVESET SET OF NARRATIVE KEY(LINENUM);
);
THINGSSET SET OF THINGS KEY(THINGID);The embedded structures can be transformed to disjoint structures as follows:
THINGS DATA SET
(
THINGID NUMBER(8);
.
.
.
);
THINGSSET SET OF THINGS KEY(THINGID);
NARRATIVE DATA SET
(
THINGID NUMBER(8);
LINENUM NUMBER(3);
LINE ALPHA(72);
);
NARRATIVESET SET OF NARRATIVE KEY(THINGID, LINENUM);The lines of narrative for a particular thing, X, can be found as follows:
SET NARRATIVESET TO BEGINNING; DO FIND NEXT NARRATIVESET AT THINGID=X : RSLT UNTIL RSLT;
If the embedded structures in the university database example are converted to disjoint structures, the database relationship diagram for that database is as illustrated in Figure D–11. (In Figure D–11, MSF is the master student file.)
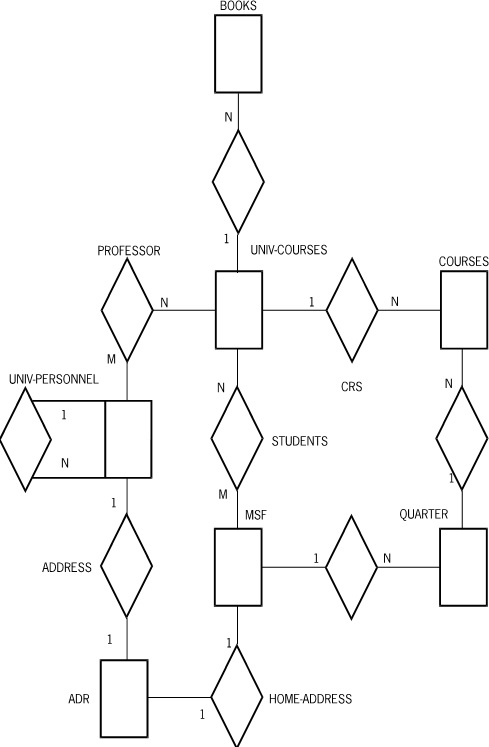
Once embedded structures have become disjoint, they can be entered directly instead of first going through the master. For instance, in the preceding university database example, questions about books can be asked directly. This suggests that perhaps the relationship between BOOKS and UNIV-COURSES should be M-to-N instead of one-to-N. Thus, a database can tend to become more general when embedded structures are changed to disjoint structures.
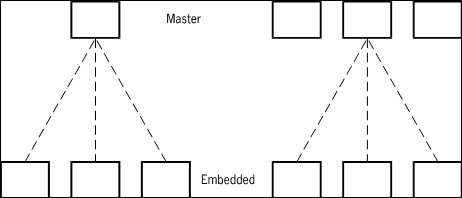
If embedded data sets are used in a database, they could be represented as shown in Figure D–12.
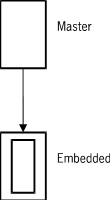
The embedded data set can have a border width of N, where N is the nesting depth in the hierarchy. Alternatively, the nesting level can be written as an integer inside the rectangle for the embedded data set. The arc connecting the embedded data set to its master data set has an arrow which indicates that the records of the embedded data set do not exist except in relation to the records of the disjoint data set and cannot be retrieved unless the master record is current.
Figure D–13 illustrates the embedded data sets at the record level.