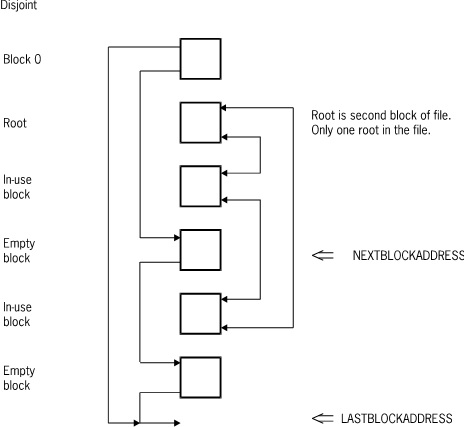
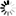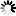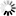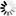The following figure illustrates an unordered data set.
The following figure illustrates an unordered data set with embedded data sets.
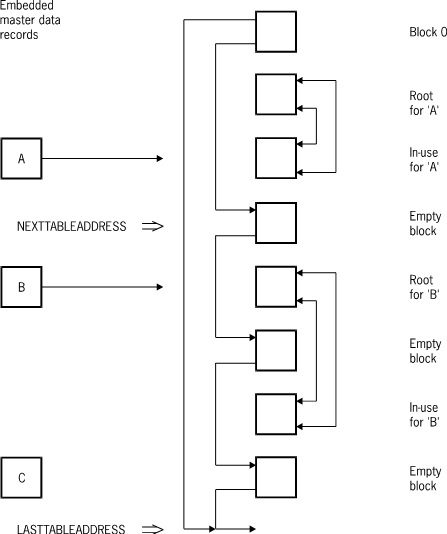
In-use data blocks form a two-way circularly linked list which is headed by the root block. Unordered data sets can be declared at either the disjoint or embedded level. For disjoint data sets, there is one chain of blocks, and the root block is the second block of the file. For embedded data sets, there is one chain for each master, and each block contains records belonging to only one master. Records are not maintained in logical order.
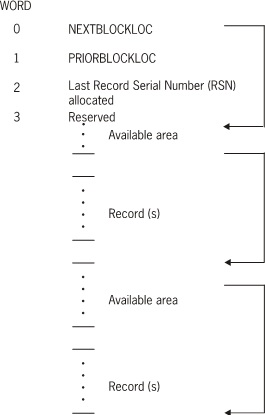
The following figure illustrates the in-use block format.
The available areas are maintained in a one-way linked list which is kept in order of increasing offset in the block. Contiguous available areas are always merged.
NEXTBLOCKLOC Layout
The following figure illustrates the NEXTBLOCKLOC layout of an unordered data set.
Example 30. Unordered Data Set NEXTBLOCKLOC Layout
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A 47: 28 BAF
Block address of next block.
* 19: 04 Unused
Zeros.
B 15: 16 NEXTAVAILLINK
Availroot. Word offset to first
available area. (= Block size if none.)PRIORBLOCKLOC Layout
The following figure illustrates the PRIORBLOCKLOC layout of an unordered data set.
Example 31. Unordered Data Set PRIORBLOCKLOC Layout
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A A A A A A A * B B B B
A 47: 28 BAF
Block address of prior block.
* 19: 04 Unused
Zeros.
B 15: 16 NEXTAVAILLINK
Assignroot. Head of list of record slots
in current block reserved for records,
but not completely stored yet.Data blocks can contain both valid records and available space. Contiguous available areas are always merged. Available areas within blocks are located using a one-way linked list which is kept in order of increasing offset in the block. A link word is maintained in the first word of each available area.
Available Area Format
The following figure illustrates the available area format of an unordered data set.
Link Word Layout
The following figure illustrates the link word layout of an unordered data set.
Example 33. Unordered Data Set Link Word Layout
A A A A B B B B C C C C
A A A A B B B B C C C C
A A A A B B B B C C C C
A A A A B B B B C C C C
A 47: 16 SELFLINK
Value = word offset of this word.
This field is useful when doing FIND NEXT
operations. If selflink field NEQ offset, then
this must be a data record. Otherwise, it can
be either a data record or an available area.
B 31: 16 NEXTDATALINK
Word offset to first word of next data
record after this available area.
(= BLOCKSIZE if none.)
C 15: 16 NEXTAVAILLINK
Word offset of next available area after
this one. (= BLOCKSIZE if none.)
Note: Contiguous available areas are
always merged.Each link field contains three pointers: one to the next available area, another to the next data record, and the last to itself. The selflink is used during a FIND NEXT operation to differentiate between valid records and available areas. When the selflink field does not equal the current offset in the block, the area must contain a data record; otherwise, the area can contain either a valid record or an available area. In the latter case, it might be necessary to follow the chain of available areas to find the valid records by a process of elimination.
Records in an unordered data set can be either fixed or variable-format. There are no significant differences in the way the two are handled. For variable-format records, the record length is determined by examining the record type item in the first word of the record. Unlike variable-format standard data sets, available areas are coalesced and can be reused by any record type.
Empty blocks are linked together in a one-way chain as described under “Common Features” earlier in this appendix. Block 0 (zero) serves as the head of the empty block chain.
Unordered Data Set Restrictions
The following restrictions apply to unordered data sets:
-
Unordered data sets can be disjoint or embedded, but are very inefficient if used as disjoint.
-
Bit vectors cannot be declared.
The restrictions on the unordered data sets are for the following reasons:
-
Disk space utilization for the disjoint case is efficient. When unordered data sets are embedded, block size must be chosen carefully since records under different masters cannot share blocks. For embedded data sets, a large block size tends to waste space because of partially filled blocks.
-
Efficient creation of new records depends upon locating available space quickly. In general, space allocation works well when few blocks are present in the chain, but can be costly when many blocks are present because each block (or each block under a master) must be read to see whether it contains free space. To avoid this problem, especially in initial load situations, the ALLOCATE FROM END option can be specified. In this case, the system examines only the first and last blocks of the chain before allocating a new block. This, of course, prevents available space in intermediate blocks from being reused.
-
Record deletion and modification are relatively efficient.
-
Both disjoint and embedded unordered data sets can be accessed in physical order using FIND NEXT and FIND PRIOR operations. These operations are efficient unless there are many deleted records. Records are accessed in physical order within blocks. In most cases, valid records can be immediately determined because their first word does not contain a valid selflink value. (Refer to the description of selflinks under “Link Word Layout” earlier in this appendix.) Increasing the BLOCKSIZE improves performance, at a potential cost in wasted space, for both the disjoint and embedded cases.