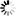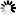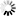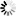── FIND ─┬────────────────────────────────┬────────────────────────────┤
└─<target specs>──<find options>─┘<target specs>
┌◄────────────────────────────── , ─────────────────────────────┐
──┴─┬──────────────────────────────────────┬─<dlm>──<text>──<dlm>─┴────┤
│ ┌◄─────────────────────────────────┐ │
└─┴─┬─/1\─ LITERAL ────────────────┬─┴─┘
├─/1\─ CASED ──────────────────┤
├─/1\─ UNCASED ────────────────┤
└─/1\─┬──────────────┬─<count>─┘
└─ OCCURRENCE ─┘<find options>
──┬──────────────────────────────────────────────────────────────┬─────┤
│ ┌◄─────────────────────────────────────────────────────────┐ │
└─┴─┬─/1\─<file title>─────────────────────────────────────┬─┴─┘
├─/1\─<sequence range list>────────────────────────────┤
├─/1\─ @ ──<start column>─┬────────────────────────────┤
│ └─ - ──<end column>──────────┤
└─/1\─ : ─┬─ FILE ──<dest file name>─┬─────────────────┤
│ └─ , ── NOCRUNCH ─┤
│ ┌◄───────────────────────────┐ │
├─ TEXT ─┴─┬────────────────────────┬─┴──────┤
│ └─ , ─┬─/1\─ PAGEFORMAT ─┤ │
│ ├─/1\─ SQUASHED ───┤ │
│ └─/1\─ TRUNCATED ──┘ │
└─ PAGEMODE ─┬───────────────────────────────┤
└─ DOWN ──<integer>─────────────┘
<count>
──<integer>────────────────────────────────────────────────────────────┤
<dest file name>
──<file name>──────────────────────────────────────────────────────────┤
Explanation
The FIND command searches a file (by default, the work file) for appearances of the specified target text. The line numbers of lines containing the target text are displayed at your terminal with an asterisk (*) denoting line numbers on which the target text appears more than once.
The output option TEXT displays the lines of text in addition to the line numbers. The FILE output option directs the lines of text to a new file instead of the terminal. The PAGEMODE option displays the first screen of text that contains the line of the target text.
<target specs>
The target specifications define the text that is the target of your search. You can define the target and method of your search with the following:
-
The <dlm> <text> <dlm> construct defines the target text.
-
The LITERAL option uses the literal search mode.
-
The CASED option uses a case-sensitive target search mode.
-
The UNCASED option uses a case-insensitive target search mode.
-
The OCCURRENCE <count> option seeks the nth occurrence of the target.
-
The <count> option seeks the specified number of occurrences of the target.
<dlm> <text> <dlm>
The <dlm> <text> <dlm> construct specifies the target text, which must be bounded by two matching delimiters (<dlm>). In a single FIND command, one or more target text strings can be the subject of the search. The text can contain any characters, except the character that is used as the delimiter, and cannot be null.
The target text is optional only when a FIND command with a specified target was previously executed. The previously specified target is used as your current FIND command target.
If a hexadecimal escape character is set through the CANDE command ESCAPE, then the target text can contain hexadecimal values delimited by the defined hexadecimal escape character. However, the target delimiter cannot be the same as the hexadecimal escape character.
The following example shows a target text string containing a hexadecimal value. The hexadecimal escape character, defined as the dollar sign ($), delimits the EBCDIC hexadecimal value and the slash (/) delimits the target text.
FIND /abc$ 00 74 $xyz/
For more information about the hexadecimal escape character, refer to the ESCAPE command earlier in this section.
LITERAL
The LITERAL option specifies that the mode of search for the target text is literal mode. The default search mode, when LITERAL is not specified, is token mode. These search modes are described later in this explanation under the topic “Understanding Token and Literal Text Mode Searches.”
By default, the text search mode is case-insensitive.
This default, however, can be overridden by the CASED and UNCASED options of the FIND command.
The CASED option enables you to search for the target text with the specified casing. That is, the search for target text is case sensitive. CASED is a command-level option and as such, overrides the CANDE session setting of the text search mode.
Refer to the SO command in this section for information about setting the text search mode for the CANDE session level.
The UNCASED option enables you to search for the target text without regard to the casing of the text. The search for target text is case insensitive. UNCASED is a command-level option and as such, overrides the CANDE session setting of the text search mode. Although UNCASED is the default search mode for FIND, the option can be specified if the current search mode is not known.
Refer to the SO command in this section for information about setting text search mode for the CANDE session level.
OCCURRENCE <count>
When you use the OCCURRENCE option with a count value, the FIND command locates and displays the line number of the nth occurrence of the target specified by the count. If the target occurs more than once on a particular line, each occurrence on that line is counted.
You can display both the line number and the text of the line that contains the target by appending :TEXT to the FIND command. If the count value is greater than the actual number of times the target text occurs in the file, then nothing is displayed.
If more than one target text string is specified, the count value applies only to its associated target text. For example, the following FIND command searches for the fifth occurrence of only the first target, but all occurrences of the second target.
FIND OCCUR 5 /accesscode/, /ARRAY/ : TEXT
The count value must be an integer from 1 through 255.
<count>
If the count value is specified without the OCCURRENCE option, all occurrences of the target text for the specified count is listed. The target is sought from the beginning of the file, or for a specified sequence range and column range of the file.
<find options>
The find options enable you to specify a particular file to search, determine where to search for the target within that file, and decide how the search target is to be returned to you for your use.
<file title>
The file title identifies the file to be searched. The file can be any file you are allowed access to. When a file title is not specified, the work file is searched.
If you use the PAGEMODE option, only the work file can be searched—you cannot specify a file title with the FIND command when you use the PAGEMODE option.
<sequence range list>
The sequence range list restricts the text search to one or more line sequence ranges. The following example restricts the search for target text to two sequence ranges:
FIND ?local area network? 250000-420000, 910000-END
Refer to Basic Constructs for the syntax diagram, definition, and explanation of sequence range list.
@ <start column>
@ <start column> –<end column>
The at sign (@) option restricts the search to a column range on each line. The start column specifies the column number in which the search is to begin. The end column specifies the column number in which the search is to end.
The column range can specify any part of the usable line except the sequence number field (for example, @81-90 is valid for type ALGOL files, but @73-80 is invalid). The entire text field of the line is searched if no columns are specified. The text field is determined by the file type.
If only a start column is specified, then only that column of each record is searched.
If the start column is in the ID field, the search is performed in the ID field. A page starting with the line number on which the target is found in the ID field is displayed for the PAGEMODE option.
:FILE
The FILE option writes the entire line containing the target text to a new file in your library. The destination file name specifies the name of that new file. The new file is the same type as the work file or file on which the search is performed.
Files created by the FIND command are crunched by default. If you do not want a crunched file, specify the output option NOCRUNCH.
If the specified destination file already exists in your library, an error message is displayed.
The <dlm> character can be any special character except semicolon (;), comma (,), at sign (@), or colon (:).
:TEXT
The TEXT option displays the entire line containing the target text, including the sequence number. When you use the TEXT option, all lines that are marked with a current MARKID have an asterisk between the sequence number and the contents of the line.
For more information about the MARKID, refer to the GET command, the MAKE command, and the MARKID command.
You can choose three output formats with the TEXT option:
-
PAGEFORMAT
Displays the output in a format similar to the page-mode output. That is, the full length of the sequence number field is displayed, immediately followed by the contents of the text field (the blank or asterisk flag character is omitted).
-
SQUASHED
Prints a sequence of blanks as a single blank.
-
TRUNCATED
Truncates the output line to the character width of the terminal, if necessary. By default, lines that exceed the terminal width are split across two or more lines.
:PAGEMODE
When you specify the PAGEMODE option with the FIND command, CANDE invokes page mode and displays the first page of the work file in which the target text is found. The PAGEMODE option applies only to a work file.
Because it is assumed that you want to continue to search for additional occurrences of a target, +FIND appears in the home position at the top of the page instead of NEXT+.
The +FIND command locates the next page on which the target appears.
You can make any editing changes to the text in page mode as usual; when you transmit the page, the change is updated to the work file and the +FIND command is performed.
:PAGEMODE DOWN <integer>
The DOWN option of PAGEMODE enables you to determine where the target line appears on the screen. The value you use for the DOWN option shifts the target line down the specified number of lines from the top of the displayed page. You can use any integer value between 0 (zero) and the size of the page on your screen minus two lines. For example, if your screen size is 24 lines, the range of values for the DOWN option is 0 to 22 lines.
If you want the target text to appear on the seventh line from the top of the screen, enter the following command:
FIND $EBCDIC$ :PAGEMODE DOWN 6
The following are exceptions for the DOWN option:
-
If the DOWN option is 10 and the target is on the second line of the file, the page is displayed with no shift of text.
-
If the DOWN option is greater than the size of the page on your screen, an error message is displayed and the DOWN option remains the default. The default for the DOWN option is set through the TERMINAL command.
-
If PAGEMODE is specified without the DOWN option, the default value (as defined by the TERMINAL command) is used.
-
If the DOWN option value is greater than the size of the file, the page is displayed without a shift of sequence lines.
FIND Command Without Target Specifications
The FIND command without any target specifications retains the target specification from the previously executed FIND command and performs the target search.
The FIND command without target specifications ignores the PAGEMODE and DOWN options specified in the previously executed FIND command. The line numbers of the file in which the targets are found are displayed. If no previous target was specified, an appropriate error message is displayed and the FIND operation is terminated.
Retaining the DOWN Option Value across FIND Commands
When page mode is invoked through the FIND command with the DOWN option specified, the DOWN option value is retained for all subsequent +FIND commands until another DOWN option value is specified. If the DOWN option is again specified in a +FIND command, the new value is applied for subsequent +FIND commands until the value is changed.
The command-level specification (FIND and +FIND commands) for the DOWN option has precedence over the session-level specification, which is specified with the TERMINAL command.
Understanding Token and Literal Text Mode Searches
CANDE uses two text-searching modes:
-
Token search mode
-
Literal search mode
Both the FIND and the REPLACE commands use these text searching modes. A token mode search is performed by default. You can invoke the literal mode search by using the LITERAL option.
In literal mode, each line of the file is considered an arbitrary string of characters, including blanks. The search is successful whenever the sequence of characters in the target text exactly matches a sequence of characters in a line of the file. For example, if the target is lit.a - b. (periods are used as <dlm> characters), the following lines contain examples of matching target text:
x = a - b x = aa - b x = a - bb
However, the target lit.a-b. is not found in those lines.
In token mode, each line is considered a sequence of tokens. The file type on which the FIND is performed determines the characters that are recognized as tokens. A token is defined for the following file types:
-
For ALGOL, DCALGOL, DMALGOL, NDLII, NEWP, and Pascal files, one of the following:
-
Any string of adjacent alphanumeric characters (uppercase and lowercase letters, digits 0 through 9) and underscores (_)
-
A single nonalphanumeric graphic character that is not an underscore or a blank
-
-
For COBOL, COBOL74, and DASDL files, one of the following:
-
Any string of adjacent alphanumeric characters (uppercase and lowercase letters, digits 0 through 9) and hyphens (-)
-
A single nonalphanumeric graphic character that is not a hyphen or a blank
-
-
For all other file types, one of the following:
-
Any string of adjacent alphanumeric characters (uppercase and lowercase letters, digits 0 through 9)
-
A single nonalphanumeric graphic character that is not a blank
-
Any number of blanks can separate tokens; at least one blank must separate adjacent alphanumeric tokens. For example, the following line illustrates the use of tokens:
100 abc, def5-3xyz i j k& *+@ end_token
The preceding line contains the following tokens:
|
ALGOL, DCALGOL, DMALGOL, NDLII, NEWP, Pascal Files |
COBOL, COBOL74, DASDL Files |
Other Files |
|---|---|---|
|
abc |
abc |
abc |
|
, |
, |
, |
|
def5 |
def5-3xyz |
def5 |
|
-- |
|
-- |
|
3xyz |
|
3xyz |
|
i |
i |
i |
|
j |
j |
j |
|
k |
k |
k |
|
& |
& |
& |
|
* |
* |
* |
|
+ |
+ |
+ |
|
@ |
@ |
@ |
|
end_token |
end |
end |
|
|
_ |
_ |
|
|
token |
token |
The search is successful whenever the same sequence of tokens in the target text is found in a line of the file. More than one token can be included in one text construct. As examples, depending on the file type, the following targets might or might not be found in line number 100 in the previous example (periods are used as delimiters):
|
Target |
File Type |
|---|---|
|
.abc. |
Found for all file types |
|
.def5-3xyz. |
Found for file types COBOL, COBOL74, and DASDL only |
|
.end_token. |
Found for ALGOL, DCALGOL, DMALGOL, NDLII, NEWP, and Pascal files only |
The following targets would not be found in line number 100 in any file type:
.a. .5. .k&.
Examples
The examples demonstrating the FIND command features use the following file:
LIST FILE1 #FILE (UZER)FILE1 ON USERFILES 100 THIS IS A LIST. 200 THIS IS A PAGE. 300 HERE IS SOME CODE. 400 SECOND LIST. 500 END. 600 Case Sensitive LisT. #
Example 1
The following shows the FIND command that searches for the target text string “LIST” and lists the lines (and text) in which the target is found:
FIND /LIST/:T #WORKFILE FILE1 100 THIS IS A LIST. 400 SECOND LIST. #
Example 2
The following shows the FIND command that searches for three target text strings within the specified sequence range (300-END) of the work file:
FIND /LIST/,/PAGE/,/CODE/ 300-END #WORKFILE FILE1 300, 400 #
Example 3
The following shows the FIND command that searches for two target text strings in literal search mode and lists the lines (and text) in which the targets are found:
FIND LITERAL /HIS/, LIT /IST/:T #WORKFILE FILE1 100 THIS IS A LIST 200 THIS IS A PAGE. 400 SECOND LIST. #
Example 4
The following shows the FIND command that searches for the fourth occurrence of a target text string in literal search mode and lists the lines (and text) in which the target is found:
FIND LIT OCCUR 4 /IS/:T #WORKFILE FILE1 200 THIS IS A PAGE. #
Example 5
The following shows the FIND command that searches for the target text in a specified file and lists the lines (and text) in which the target is found. The asterisks immediately following the sequence numbers indicate the lines were marked with the current MARKID.
FIND /LIST/ FILE1:TEXT #FILE (UZER)FILE1 ON USERFILES 100*THIS IS A LIST. 400*SECOND LIST.
Example 6
The following shows the FIND command that performs a case sensitive search for the target text in a specified file and lists the lines (and text) in which the target is found.
FIND CASED /LisT/ FILE1:TEXT #FILE (UZER)FILE1 ON USERFILES 600 Case Sensitive LisT