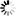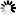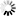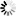┌◄──────────────────────────────────────────────────────┐
── MATCH ─┴─┬─/1*\─<old file>─┬─────────────────────────────────┬─┴────┤
│ └─ TO ──<new file>────────────────┤
├─/1\─<sequence range list>─────────────────────────┤
├─/1\─ @ ──<start column>─┬─────────────────────────┤
│ └─ - ──<end column>───────┤
├─/1\─ SEQ ── = <start column> ─┬───────────────────┤
│ └─ - ──<end column>─┤
└─/1\─ : ──<match output options>───────────────────┘<match output options>
──┬─ FILE ──<file name>─┬─────────────────────────────┬────────────────┤
│ │ ┌◄───────── , ────────┐ │
│ └─ , ─┴─┬─/1\─┬─ COMPARE ─┬─┴─┤
│ │ └─ RESULT ──┤ │
│ └─ EQUAL ─────────┘ │
└─ TEXT ─┬──────────────────────────────────────────┤
│ ┌◄─────── , ───────┐ │
└─ , ─┴─┬─ SQUASHED ───┬─┴─────────────────┘
├─ TRUNCATED ──┤
├─ COMPARE ────┤
├─ EQUAL ──────┤
└─ PAGEFORMAT ─┘<new file>
──<file name>──────────────────────────────────────────────────────────┤
<old file>
──<file name>──────────────────────────────────────────────────────────┤
Explanation
The MATCH command compares two files and determines the differences between them. Output indicating the result of the comparison can be directed to the terminal or to a new file. The <old file>, or portions thereof, is compared with the <new file>. If a new file is not specified, the work file is used by default.
If two sequenced files have a record with the same sequence number, the records are compared character by character. If the two records are found to differ, the new file record is written as a replacement line. If a record exists at a sequence number in the old file but does not exist in the new file, that record is written as a deleted line. If a record exists at a sequence number in the new file but not in the old file, that record is written as an inserted line.
For unsequenced files, the first record of the old file is compared character by character with the first record of the new file, the second record is compared with the second record, and so forth. If the two records differ, the new file record is flagged as a replacement line. If the old file contains more records than the new file, then all of the extra records in the old file are flagged as deleted lines. Conversely, if the new file contains more records than the old file, all extra records in the new file are flagged as inserted lines.
Any two files that are compared with the MATCH command must have the same file type.
If a <sequence range list> is specified, the files are compared only within that sequence range. If a column specification is used (for example, @ <start column>), the records are compared within that column range. If the SEQ option is used, the indicated column range is used as sequence numbers for the comparison. The width of this sequence number cannot exceed eight digits, and the option can be used only with DATA files.
The results of the comparison are formed according to the output options used. By default, output is directed to the terminal and lists only the sequence numbers. Line deletions are preceded by a minus sign (–), line replacements by an R, and line insertions by an I.
The FILE <file name> option directs output to the specified file. In that file, line deletions are preceded by a minus sign (–), replacements by an R, and insertions by an I. The resultant file is of type CDATA by default. However, if the RESULT option is used, the output file is the same file type as that of the files being compared. Files created with the MATCH command are unconditionally crunched. If a file entitled <file name> already exists in the user's library, an error message is displayed.
If the COMPARE option is specified, a file named <file name> is created that contains the nonmatching lines in the two files being compared. The comparison file contains the original version of each line in the old file that has been deleted by a DELETE command or changed by a single-line entry or FIX command in the new file. The comparison file also contains new lines of text in the new file flagged as follows:
-
Each old line replaced by a new line is flagged with an R.
-
Each new line inserted is flagged with an I.
-
Each line that has been modified by a FIX is listed and flagged with an F.
Blank lines are inserted to separate the listing into groups; a group contains the original version of a line of text followed by the new (fixed, replaced or inserted) line of text. Consecutively inserted or deleted lines are shown as a single group.
If the RESULT option is used, the result file is the same file type as that of the files compared with the MATCH command.
When the RESULT option is used for language source files (for example, ALGOL and FORTRAN), line insertions and replacements are put in the result file. Single-line deletions are replaced by a compiler control record (CCR)—that is, an otherwise blank record with a dollar sign ($) in column one. Multiple-line deletions in sequence cause the output of a $SET VOIDT record at the starting sequence number and a $POP VOIDT at the ending sequence number. Most compilers recognize these records as deletions. Refer to the appropriate language reference manual for more information about compiler control records (CCRs) and compiler control options.
For DATA file comparisons using the sequence number column specification, line replacements and insertions are put in the result file. For deletions, a blank record is put in the file with sequence number intact.
When records differ in DATA file comparisons not using the sequence number column specification, the new file record is placed in the result file. If the new file is longer than the old file, trailing unmatched records are placed in the result file. If the old file is longer than the new file, the trailing unmatched records are not placed in the result file.
If the EQUAL option is used, equal records are placed in the output.
The TEXT option directs output to the terminal using the default specifications.
If the SQUASHED option is used, any group of multiple blanks is reduced to a single blank for output of the record.
If the TRUNCATED option is used, a line too long for the terminal is truncated to fit on one terminal line.
If the PAGEFORMAT option is specified, the output appears in a format similar to the page mode output. That is, the full length of the sequence number field is displayed, immediately followed by the contents of the text field (the blank or asterisk flag character is omitted).
Examples
L 100 THIS IS IN BOTH FILES 200 DIFFERENT COLUMNS 300 SAME COLUMNS 400 NEW FILE # LIST A/B #FILE (UZER)A/B ON USERPACK 100 THIS IS IN BOTH FILES 150 OLD FILE 200 DIFFERENT COLUMNS 300 SAME COLUMNS # MATCH A/B:T,C #UPDATING #MATCHING A/B TO WORKFILE -150 OLD FILE -200 DIFFERENT COLUMNS R200 DIFFERENT COLUMNS 300 SAME COLUMNS I400 NEW FILE # MATCH A/B TO WORKFILE @15-20 #MATCHING A/B TO WORKFILE -150,R200,I400